I have ongoing research projects in the following application areas. See Papers for a publication list.
|
Structure: Protein bioinformatics
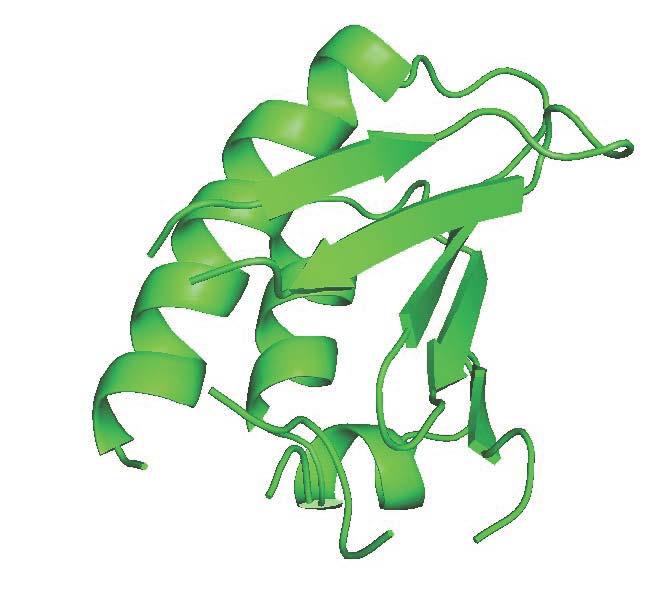
Predicting the 3-D structure of a protein from its amino acid sequence using computational methods is a highly challenging problem, and has long captured the attention of researchers across computational biology, chemistry, medicine, and computer science. The size of the Protein Data Bank (PDB) has grown rapidly over the years, but the number of proteins of interest that have not or cannot be determined experimentally (X-ray, NMR) outpaces that growth. Thus there is a need for computational methods to determine the structure of new proteins, when there is no similar structure in the database. For this purpose two main ingredients are required, which are directly intertwined: a sampling method to generate possible conformations of the protein, and an energy or scoring function to evaluate conformations. The conformational space of a protein is vast, even after accounting for protein geometry, which poses the significant bottleneck for computational methods. We are developing more efficient stochastic methods to enable a targeted exploration of low-energy conformations. This, in turn, can generate the necessary data to help us develop more accurate scoring functions.
|
|
Complex systems: Inference for dynamic systems
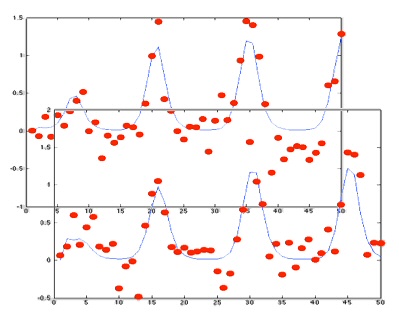
Dynamic systems, often described by sets of differential equations, are widely used in modeling diverse behaviors in science. Examples of these include the modeling of mRNA and protein levels in cultured cells, and gene regulatory networks with feedback loops. Historically, dynamic systems have mainly been used for conceptual or theoretical understanding rather than data fitting, as experimental data was limited. This has changed with experimental techniques having been greatly improved, now capable of following systems in real time yielding dynamic data. This presents interesting statistical questions concerning the estimation of the parameters in the models. Dynamic systems in cells can involve hundreds of genes, so we are interested in developing approximate inference methods that can scale well and are computationally efficient.
|
|
Real-time imaging: Enhanced assessment of wood products

The big data era is also transforming "traditional" industries such as wood products. In the past, the quality of construction lumber was assessed by humans visually examining each piece of a representative sample. Modern mills now employ laser imaging technology, producing detailed scans of each side of lumber pieces as they are being cut from trees. In collaboration with wood scientists, we are exploiting these image data to develop more accurate methods of predicting the strength of lumber: for example, in what ways are the spatial arrangement of knots on a piece indicative of strength? Fast computational methods are also under development for use to assess pieces automatically, in real-time, as they are being processed in mills.
|